Welcome to GongMH's Blog!
keep study.-
shell解析yaml文件
在有些场景下,想要解析yaml文件,但是环境受限只能使用shell脚本,不能使用python等高级语言解析。调研后,本文记录下解析shell脚本,以备后用。
shell解析函数如下,
function parse_yaml { local prefix=$2 local s='[[:space:]]*' w='[a-zA-Z0-9_]*' fs=$(echo @|tr @ '\034') sed -ne "s|^\($s\):|\1|" \ -e "s|^\($s\)\($w\)$s:$s[\"']\(.*\)[\"']$s\$|\1$fs\2$fs\3|p" \ -e "s|^\($s\)\($w\)$s:$s\(.*\)$s\$|\1$fs\2$fs\3|p" $1 | awk -F$fs '{ indent = length($1)/2; vname[indent] = $2; for (i in vname) {if (i > indent) {delete vname[i]}} if (length($3) > 0) { vn=""; for (i=0; i<indent; i++) {vn=(vn)(vname[i])("_")} printf("%s%s%s=\"%s\"\n", "'$prefix'",vn, $2, $3); } }' }脚本中的解析函数调用格式为:
parse_yaml <path_to_conf.yaml> <prefix>。调用后就会有prefix为前缀的配置变量。例如,yaml文件内容如下:
#conf_path: ~/conf.yaml ## global definitions global: debug: yes verbose: no debugging: detailed: no header: "debugging started" ## output output: file: "yes"执行解析配置文件
eval $(parse_yaml "~/conf.yaml" "conf_")输出解析后的一些配置值
echo $conf_global_debug #output: yes echo $conf_global_debugging_header #output: debugging started echo $conf_output_file #output: yes如上,我们就解析出来对应的配置了~
-
golang基础-06-map的存储结构
在开发过程中,经常通过map实现kv数据的处理。源码
src/runtime/map.go中可以看到map的底层结构,网上也有很多对map的分析,此处不再赘述。本文先综述map的结构,然后根据具体的一个map变量分析map底层是怎么存储的。1. 内存中的map的结构
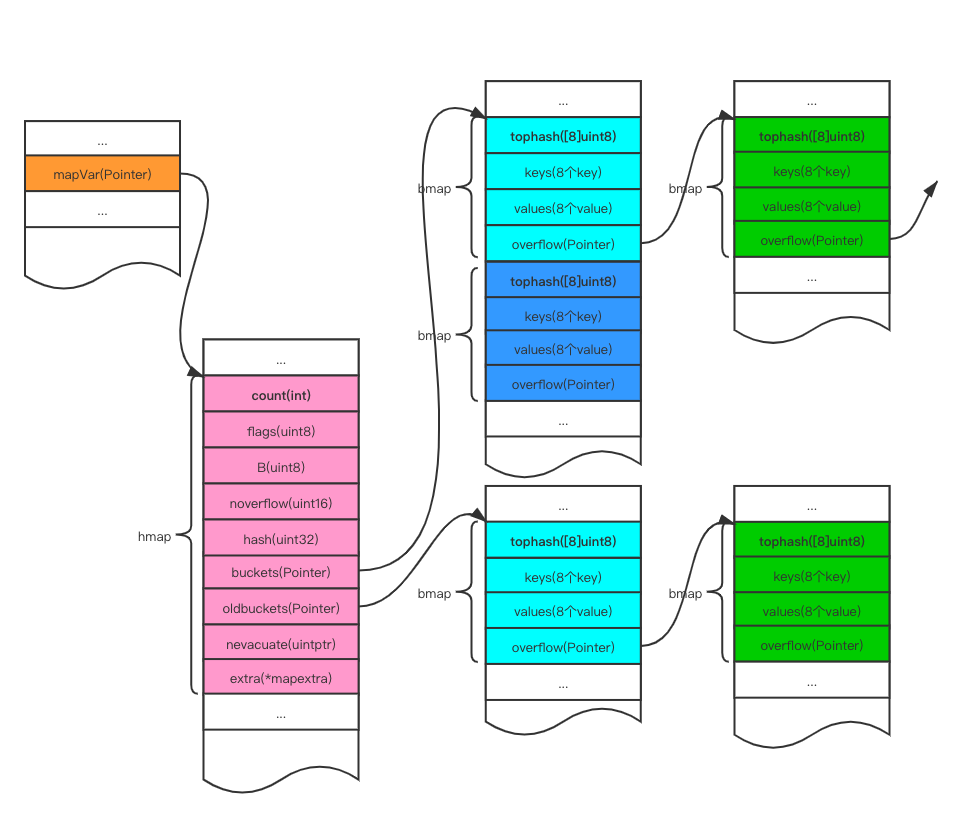
map的实现是通过hash来实现,底层是一个hmap和若干个bmap组成,基本结构见上图。
总结下来就是以下几点:
1. map变量是一个指针,指向hmap结构体; 2. hmap中包含map中元素的个数count,桶的个数(2^B),桶数组的地址`buckets`等, 3. hmap的元素`buckets`指向bmap的数组,根据hash确定key落入哪个bmap中; 4. hmap的元素`oldbuckets`指向扩容阶段之前的bmap的数组; 5. bmap中tophash用来快速定位key是否在这个bmap中; 6. bmap中8个kv槽位用来存储key和value; 7. bmap中overflow用来拉链指向新的桶,解决添加超过key时,超过8个槽位的情况;
-
golang基础-05-数组&切片&string变量的存储结构
上文分析了,单个基础变量的内存存储结构,下面我们分析下基础变量组合形式的变量。
1. 数组(array)
对
int32的数组进行分析,运行一下。package main import ( "fmt" "unsafe" ) func main() { var arrVar = [...]int32{ 'b', 2, 3, 4, } fmt.Printf("arrVar 值: %d\n", arrVar) fmt.Printf("arrVar 内存地址: %p\n", &arrVar) fmt.Printf("arrVar 内存中占总字节数:%d\n", unsafe.Sizeof(arrVar)) fmt.Printf("arrVar 元素个数:%d\n", len(arrVar)) //第一个元素 ptr1 := (*int32)(unsafe.Pointer(&arrVar)) fmt.Printf("arrVar 第一个元素,地址=%x,值: %d\n", ptr1, *ptr1) //第二个元素 ptr2 := (*int32)(unsafe.Pointer(uintptr(unsafe.Pointer(&arrVar)) + uintptr(4*1))) fmt.Printf("arrVar 第二个元素,地址=%x,值: %d\n", ptr2, *ptr2) //第三个元素 ptr3 := (*int32)(unsafe.Pointer(uintptr(unsafe.Pointer(&arrVar)) + uintptr(4*2))) fmt.Printf("arrVar 第三个元素,地址=%x,值: %d\n", ptr3, *ptr3) //第四个元素 ptr4 := (*int32)(unsafe.Pointer(uintptr(unsafe.Pointer(&arrVar)) + uintptr(4*3))) fmt.Printf("arrVar 第四个元素,地址=%x,值: %d\n", ptr4, *ptr4) }输出结果如下:
arrVar 值: [98 2 3 4] arrVar 内存地址: 0xc000016050 arrVar 内存中占总字节数:16 arrVar 元素个数:4 arrVar 第一个元素,地址=c000016050,值: 98 arrVar 第二个元素,地址=c000016054,值: 2 arrVar 第三个元素,地址=c000016058,值: 3 arrVar 第四个元素,地址=c00001605c,值: 4结果可以看出,数组的元素类型是
int32,每个占用4个字节,一共4个元素,因此数组总共占用16字节。数组的首地址是c000016050对应数组第一个元素,最后一个元素的首地址是c00001605c,可以得出数组元素连续分配,并且地址从低到高排布。2. 切片(slice)
仍然使用
int32类型,对切片进行分析,运行一下。package main import ( "fmt" "unsafe" ) func main() { var arrVar = []int32{ 'b', 2, 3, 4, } fmt.Printf("arrVar 值: %d\n", arrVar) fmt.Printf("arrVar 内存地址: %p\n", &arrVar) fmt.Printf("arrVar 内存中占总字节数:%d\n", unsafe.Sizeof(arrVar)) fmt.Printf("arrVar 元素个数:%d\n", len(arrVar)) }输出结果如下:
arrVar 值: [98 2 3 4] arrVar 内存地址: 0xc00009c020 arrVar 内存中占总字节数:24 arrVar 元素个数:4可以看出,切片4个元素,但是切片占用的总字节数为24字节。可以自行试下,无论切片多少元素,slice变量本身占用的字节数不变,都是24字节。
分析golang源码(go1.11)在文件
src/runtime/slice.go中可以看到如下结构:type slice struct { array unsafe.Pointer len int cap int }说明slice实际上是由一个指针和两个int变量组成,指针和int都是占8个字节,也就对应了上面的slice总共占用24字节。继续用
slice结构体对切片进行分析,运行一下。package main import ( "fmt" "unsafe" ) func main() { var sliceVar = []int32{ 'b', 2, 3, 4, } fmt.Printf("sliceVar 值: %d\n", sliceVar) type sliceStruct struct { array unsafe.Pointer len int cap int } //将切片转换为sliceStruct结构 ptr := (*sliceStruct)(unsafe.Pointer(&sliceVar)) fmt.Printf("sliceVar 地址=%p,值: %#v\n", &sliceVar, *ptr) //取出sliceStruct中指针,再找指针值对应地址内存的值 arrPtr := (*[4]int32)(ptr.array) fmt.Printf("sliceVar 中指针指向的值: %#v\n", *arrPtr) }执行结果如下:
sliceVar 值: [98 2 3 4] sliceVar 地址=0xc00000c060,值: main.sliceStruct{array:(unsafe.Pointer)(0xc000016050), len:4, cap:4} sliceVar 中指针指向的值: [4]int32{98, 2, 3, 4}切片对应的结构体中,元素
array指向的是切片元素存储的数组地址,元素len和cap分别对应切片的长度和容量。也对应之前知道的知识,切片底层是数组,一个数组可以被多个切片引用,感兴趣的可以自己试验下。3. 字符串(string)
字符串的结构类似切片,不过字符串是不可被改变的,也就只有指针和长度。运行一下。
package main import ( "fmt" "unsafe" ) func main() { var stringVar string = "hi" fmt.Printf("sliceVar 值: %s\n", stringVar) fmt.Printf("sliceVar 内存中占总字节数:%d\n", unsafe.Sizeof(stringVar)) type stringStruct struct { array unsafe.Pointer len int } //将切片转换为sliceStruct结构 ptr := (*stringStruct)(unsafe.Pointer(&stringVar)) fmt.Printf("sliceVar 地址=%p,值: %#v\n", &stringVar, *ptr) //取出sliceStruct中指针,再找指针值对应地址内存的值 arrPtr := (*[5]byte)(ptr.array) fmt.Printf("sliceVar 中指针指向的值: %c, %c\n", (*arrPtr)[0], (*arrPtr)[1]) }执行结果如下:
sliceVar 值: hi sliceVar 内存中占总字节数:16 sliceVar 地址=0xc000010210,值: main.stringStruct{array:(unsafe.Pointer)(0x4c1b71), len:2} sliceVar 中指针指向的值: h, i字符串包含指针和int两个元素,固定占用16个字节。其中指针指向一个byte的数组,int元素代表的是字符串的长度。
4. 总结
从以上可以看出,数组是一段连续的内存空间。而切片和字符串本身是一个指针,指针再指向具体的内容的数组。
-
golang基础-04-基础变量的存储结构
在内存中,基础变量是若干个连续地址组成的内存空间。指针指向低地址,向高地址延展。并且在计算机的内存中通常使用小端序存储,与网络流中的大端序不同的是,小端序内存低地址空间存储变量低位,内存的高地址空间存储变量的高位。
使用
unsafe包中的工具,可以对内存进行操作。下面通过int32,进行分析基础变量在内存中怎么存储,运行一下。package main import ( "fmt" "unsafe" ) func main() { var i32Var int32 = 0x12345678 fmt.Printf("i32Var 值: %x\n", i32Var) fmt.Printf("i32Var 内存地址: %p\n", &i32Var) fmt.Printf("i32Var 内存中占总字节数:%d\n", unsafe.Sizeof(i32Var)) //第一个字节 ptr1 := (*byte)(unsafe.Pointer(&i32Var)) fmt.Printf("i32Var 第一个字节,地址=%x,值: %x\n", ptr1, *ptr1) //第二个字节 ptr2 := (*byte)(unsafe.Pointer(uintptr(unsafe.Pointer(&i32Var)) + uintptr(1))) fmt.Printf("i32Var 第二个字节,地址=%x,值: %x\n", ptr2, *ptr2) //第三个字节 ptr3 := (*byte)(unsafe.Pointer(uintptr(unsafe.Pointer(&i32Var)) + uintptr(2))) fmt.Printf("i32Var 第三个字节,地址=%x,值: %x\n", ptr3, *ptr3) //第四个字节 ptr4 := (*byte)(unsafe.Pointer(uintptr(unsafe.Pointer(&i32Var)) + uintptr(3))) fmt.Printf("i32Var 第四个字节,地址=%x,值: %x\n", ptr4, *ptr4) }运行输出结果如下:
i32Var 值: 12345678 i32Var 内存地址: 0xc000016050 i32Var 内存中占总字节数:4 i32Var 第一个字节,地址=c000016050,值: 78 i32Var 第二个字节,地址=c000016051,值: 56 i32Var 第三个字节,地址=c000016052,值: 34 i32Var 第四个字节,地址=c000016053,值: 12由此看出,
int32的变量i32Var占4个字节的内存。变量的首地址是c000016050,最后一个字节地址是c000016053,也就是说变量内部的地址空间从低到高排布。第一个字节存储的值是0x78,对应整个变量值0x12345678,说明首字节存储变量的低位值,即小端序。感兴趣的话,可以自行分析其他基础类型~
-
golang基础-03-http-client
1. 引言
针对http客户端,本文提供两个基础方法
HttpGet和HttpPost。其中日志模块可以根据自己需要做更改。client的返回值,是response的byte数组,根据实际情况做解析处理即可。
2. httpGet
HttpGet运行实例,运行一下。
func main() { data := map[string]string { "key": "value", } resp, err := HttpGet("http://httpbin.org/get", data) if err != nil { return } type RespStruct struct { Args map[string]string `json:"args"` Url string `json:"url"` } var rs RespStruct err = json.Unmarshal(resp, &rs) if err != nil { return } fmt.Println("===rs.url==: ", rs.Url) }输出结果
===rs.url==: http://httpbin.org/get?key=value3. httpPost
HttpPost运行实例,运行一下。
func main() { data := map[string]string { "key": "value", } resp, err := HttpPost("http://httpbin.org/post", data) if err != nil { return } type RespStruct struct { Form map[string]string `json:"form"` Url string `json:"url"` } var rs RespStruct err = json.Unmarshal(resp, &rs) if err != nil { return } fmt.Println("===rs.form==: ", rs.Form) }输出结果
===rs.form==: map[key:value]附:http客户端lib
package helper import ( "errors" "fmt" "io/ioutil" "log" "net/http" "net/url" "strings" "time" ) //change your log var logInfo = log.Println var logFatal = log.Fatal func HttpGet(requestUrl string, data map[string]string) (response []byte, err error) { client := &http.Client{ Timeout: time.Duration(3 * time.Second), } req, err := request("GET", requestUrl, data) if err != nil { logFatal(fmt.Sprintf("http req err, err: %s", err.Error())) return response, err } resp, err := client.Do(req) if err != nil { logFatal(fmt.Sprintf("http request do err, err: %s", err.Error())) return response, err } defer resp.Body.Close() body, err := ioutil.ReadAll(resp.Body) if err != nil { logFatal(fmt.Sprintf("http request read io err, err: %s", err.Error())) return response, err } logInfo(requestUrl, data, string(body)) return body, err } func HttpPost(requestUrl string, data map[string]string) (response []byte, err error) { client := &http.Client{ Timeout: time.Duration(3 * time.Second), } req, err := request("POST", requestUrl, data) if err != nil { logFatal(fmt.Sprintf("http req err, err: %s", err.Error())) return response, err } resp, err := client.Do(req) if err != nil { logFatal(fmt.Sprintf("http request do err, err: %s", err.Error())) return response, err } defer resp.Body.Close() body, err := ioutil.ReadAll(resp.Body) if err != nil { logFatal(fmt.Sprintf("http request read io err, err: %s", err.Error())) return response, err } logInfo(requestUrl, data, string(body)) return body, err } func request(method string, requestUrl string, data map[string]string) (req *http.Request, err error) { v := url.Values{} if len(data) > 0 { for key, value := range data { v.Add(key, value) } } if method == "POST" { req, err = http.NewRequest(method, requestUrl, strings.NewReader(v.Encode())) } else { req, err = http.NewRequest(method, requestUrl+"?"+v.Encode(), nil) } if err != nil { logFatal(fmt.Sprintf("new request err, err: %s", err.Error())) return nil, err } if method == "POST" { req.Header.Set("Content-Type", "application/x-www-form-urlencoded") } return req, nil }
-
golang基础-02-字符串
字符串的相关操作也是实际项目中常用的功能。
1. 字符串声明
var str string2. 字符串长度
len(str)3. 字符串操作
strings包中包含了很多字符串的操作,例如,取子串索引
Index*,字符串切分Split*,大小写转换ToUpper*与ToLower*,去除字符Trim*,字符串替换Replace,以及字符串映射函数Map等。关于字符串相关操作的一些例子如下,也可以运行一下。
package main import ( "fmt" s "strings" "unicode" "unicode/utf8" ) func main() { var p = fmt.Println //1. func IndexByte(s string, c byte) int //IndexByte 返回c在s中第一次出现的位置,-1表示c在s中不存在 p("IndexByte:", s.IndexByte("abc", 'a')) //IndexByte: 0 p("IndexByte:", s.IndexByte("abc", 'd')) //IndexByte: -1 //2. func Count(s, substr string) int //Count 返回substr在s中出现的次数,如果substr为空返回1 + (s的unicode长度) p("Count:", s.Count("abcabc", "ab")) //Count: 2 p("Count:", s.Count("a你好c你好", "好")) //Count: 2 p("Count:", s.Count("abcabc", "ac")) //Count: 0 p("Count:", s.Count("abcabc", "")) //Count: 7 p("Count:", s.Count("abc你好", "")) //Count: 6 p("Count:", s.Count("", "")) //Count: 1 //3. func Contains(s, substr string) bool //Contains 返回s中是否包含substr p("Contains:", s.Contains("abc", "ab")) //Contains: true p("Contains:", s.Contains("abc", "ac")) //Contains: false p("Contains:", s.Contains("abc", "")) //Contains: true p("Contains:", s.Contains("", "")) //Contains: true p("Contains:", s.Contains("您好", "好")) //Contains: true //4. func ContainsAny(s, chars string) bool //ContainsAny 返回s中是否包含一个chars中的unicode字符 p("ContainsAny:", s.ContainsAny("abc", "ab")) //ContainsAny: true p("ContainsAny:", s.ContainsAny("abc", "ac")) //ContainsAny: true p("ContainsAny:", s.ContainsAny("abc", "")) //ContainsAny: false p("ContainsAny:", s.ContainsAny("", "")) //ContainsAny: false p("ContainsAny:", s.ContainsAny("您好", "好")) //ContainsAny: true //5. func ContainsRune(s string, r rune) bool //ContainsRune 返回s中是否包含unicode字符r p("ContainsRune:", s.ContainsRune("abc", 97)) //ContainsRune: true p("ContainsRune:", s.ContainsRune("abc", 100)) //ContainsRune: false p("ContainsRune:", s.ContainsRune("中国", 0x4e2d)) //ContainsRune: true 注:0x4e2d为中的unicode编码 //6. func LastIndex(s, substr string) int //LastIndex 返回substr在s中最后出现的index,-1表示c在s中不存在 p("LastIndex:", s.LastIndex("abcbc", "bc")) //LastIndex: 3 p("LastIndex:", s.LastIndex("abcbc", "cd")) //LastIndex: -1 //7. func IndexRune(s string, r rune) int //IndexRune 返回unicode字符r在s中第一次出现的位置,-1表示r在s中不存在 p("IndexRune:", s.IndexRune("abc", 98)) //IndexRune: 1 p("IndexRune:", s.IndexRune("abc", 100)) //IndexRune: -1 p("IndexRune:", s.IndexRune("s中国", 0x4e2d)) //IndexRune: 1 TODO: 需确认 p("IndexRune:", s.IndexRune("abc", utf8.RuneError)) //IndexRune: -1 //8. func IndexAny(s, chars string) int //IndexAny 返回s中第一个包含chars中的unicode字符的位置,-1表示不存在 p("IndexAny:", s.IndexAny("abc", "cdb")) //IndexAny: 1 p("IndexAny:", s.IndexAny("abc", "de")) //IndexAny: -1 p("IndexAny:", s.IndexAny("中国人", "汉人")) //IndexAny: 6 TODO: 需确认 //9. func LastIndexAny(s, chars string) int //LastIndexAny 返回s中最后一个包含chars中unicode字符的位置,-1表示不存在 p("LastIndexAny:", s.LastIndexAny("abc", "dcb")) //LastIndexAny: 2 p("LastIndexAny:", s.LastIndexAny("abc", "de")) //LastIndexAny: -1 p("LastIndexAny:", s.LastIndexAny("中国人", "汉人")) //LastIndexAny: 6 TODO: 需确认 //10. func LastIndexByte(s string, c byte) int //LastIndexByte 返回s中包含字符c的最后一个位置,-1表示不存在 p("LastIndexByte:", s.LastIndexByte("abc", 'c')) //LastIndexByte: 2 p("LastIndexByte:", s.LastIndexByte("abc", 'd')) //LastIndexByte: -1 p("LastIndexByte:", s.LastIndexByte("a中国人c", 'c')) //LastIndexByte: 10 TODO: 需确认 //11. func SplitN(s, sep string, n int) []string //SplitN 将字符串s按照sep分隔,返回分割后的字符串slice。 // n < 0 : 返回分割后所有的字符串 // n = 0 : 返回nil,即空的slice // n > 0 : 返回最多n个子串,最后一个子串不做分隔 p("SplitN:", s.SplitN("bcaddada", "a", -1)) //SplitN: [bc dd d ] p("SplitN:", s.SplitN("bcaddada", "a", 0)) //SplitN: [] p("SplitN:", s.SplitN("bcaddada", "a", 2)) //SplitN: [bc ddada] //12. func SplitAfterN(s, sep string, n int) []string //SplitAfterN 将字符串s按照sep分隔,返回分割后的字符串slice,并且每个子串都含有分隔符。 // n < 0 : 返回分割后所有的字符串 // n = 0 : 返回nil,即空的slice // n > 0 : 返回最多n个子串,最后一个子串不做分隔 p("SplitAfterN:", s.SplitAfterN("abcaddada", "a", -1)) //SplitAfterN: [a bca dda da ] p("SplitAfterN:", s.SplitAfterN("abcaddada", "a", 0)) //SplitAfterN: [] p("SplitAfterN:", s.SplitAfterN("abcaddada", "a", 2)) //SplitAfterN: [a bcaddada] //13. func Split(s, sep string) []string //Split 将字符串s按照sep分隔,返回分割后的字符串slice p("Split:", s.Split("abcaddaba", "ab")) //Split: [ cadd a] p("Split:", s.Split("abcaddada", "af")) //Split: [abcaddada] p("Split:", s.Split("abcaddada", "")) //Split: [a b c a d d a d a] //14. func SplitAfter(s, sep string) []string //Split 将字符串s按照sep分隔,返回分割后的字符串slice,并且每个子串都含有分隔符。 p("SplitAfter:", s.SplitAfter("abcaddaba", "ab")) //SplitAfter: [ab caddab a] p("SplitAfter:", s.SplitAfter("abcaddada", "af")) //SplitAfter: [abcaddada] p("SplitAfter:", s.SplitAfter("abcaddada", "")) //SplitAfter: [a b c a d d a d a] //15. func Fields(s string) []string //Fields 将字符串s根据空白符分隔为子串 //var asciiSpace = [256]uint8{'\t': 1, '\n': 1, '\v': 1, '\f': 1, '\r': 1, ' ': 1} p("Fields:", s.Fields("a\tb cc\nd")) //Fields: [a b cc d] p("Fields:", s.Fields("abcd")) //Fields: [abcd] //16. func FieldsFunc(s string, f func(rune) bool) []string //FieldsFunc 将字符串s根据自定义函数分割为子串,满足函数f的字符即为分隔符 f := func(c rune) bool { return !unicode.IsLetter(c) && !unicode.IsNumber(c) } p("FieldsFunc:", s.FieldsFunc(" foo1;bar2,baz3...", f)) //FieldsFunc: [foo1 bar2 baz3] //17. func Join(a []string, sep string) string //Join 将字符串slice a通过sep拼接起来 p("Join:", s.Join([]string{"1","a","中"}, "-")) //Join: 1-a-中 //18. func HasPrefix(s, prefix string) bool //HasPrefix 判断字符串s是否适以prefix开始 p("HasPrefix:", s.HasPrefix("abc213123", "ab")) //HasPrefix: true p("HasPrefix:", s.HasPrefix("abc213123", "ac")) //HasPrefix: false //19. func HasSuffix(s, suffix string) bool //HasSuffix 判断字符串s是否适以suffix结尾 p("HasSuffix:", s.HasSuffix("abc213123", "23")) //HasSuffix: true p("HasSuffix:", s.HasSuffix("abc213123", "2")) //HasSuffix: false //20. func Map(mapping func(rune) rune, s string) string //Map 将字符串s根据mapping函数做转换 replaceNotLatin := func(r rune) rune { if unicode.Is(unicode.Latin, r) { return r } return '?' } p("Map:", s.Map(replaceNotLatin, "Hello\255World")) //Map: Hello?World //21. func Repeat(s string, count int) string //Repeat 将字符串s重复count次,count为负数会panic,count为0返回空字符串 // overflow panic. SEE ISSUE: https://github.com/golang/go/issues/16237 p("Repeat:", s.Repeat("abc", 3)) //Repeat: abcabcabc p("Repeat:", s.Repeat("", 3)) //Repeat: p("Repeat:", s.Repeat("abc", 0)) //Repeat: //22.func ToUpper(s string) string //ToUpper 将小写字符转为大写 p("ToUpper:", s.ToUpper("a。B,cd\nfE中")) //ToUpper: A。B,CD\nFE中 //23.func ToLower(s string) string //ToLower 将大写字符转为小写 p("ToLower:", s.ToLower("a。B,cd\nfE中")) //ToLower: a。b,cd\nfe中 //24. func ToTitle(s string) string //ToTitle 将字符串s转为title p("ToTitle:", s.ToTitle("hello Go")) //ToTitle: HELLO GO p("ToTitle:", s.ToTitle("хлеб")) //ToTitle: ХЛЕБ //25. func TrimLeftFunc(s string, f func(rune) bool) string //TrimLeftFunc 对字符串s,从前到后判断字符是否满足f,满足则去除并继续判断,不满足返回剩余字符串 f25 := func(r rune) bool { return !unicode.IsLetter(r) && !unicode.IsNumber(r) } p("TrimLeftFunc:", s.TrimLeftFunc("¡¡¡Hello, Gophers!!!", f25)) //TrimLeftFunc: Hello, Gophers!!! //26. func TrimRightFunc(s string, f func(rune) bool) string //TrimRightFunc 对字符串s,从后到前判断字符是否满足f,满足则去除并继续判断,不满足返回剩余字符串 f26 := func(r rune) bool { return !unicode.IsLetter(r) && !unicode.IsNumber(r) } p("TrimRightFunc:", s.TrimRightFunc("¡¡¡Hello, Gophers!!!", f26)) //TrimRightFunc: ¡¡¡Hello, Gophers //27. func TrimFunc(s string, f func(rune) bool) string //TrimFunc 对字符串s,从两端判断字符是否满足f,满足则去除并继续判断,不满足返回剩余字符串 f27 := func(r rune) bool { return !unicode.IsLetter(r) && !unicode.IsNumber(r) } p("TrimFunc:", s.TrimFunc("¡¡¡Hello, Gophers!!!", f27)) //TrimRightFunc: Hello, Gophers //28. func IndexFunc(s string, f func(rune) bool) int //IndexFunc 字符串s中第一个满足f的的索引,-1表示没有符合条件的字符 f28 := func(c rune) bool { return unicode.Is(unicode.Han, c) } p("IndexFunc:", s.IndexFunc("Hello, 世界", f28)) //IndexFunc: 7 p("IndexFunc:", s.IndexFunc("Hello, world", f28)) //IndexFunc: -1 //29. func LastIndexFunc(s string, f func(rune) bool) int //LastIndexFunc 字符串s中第一个满足f的的索引,-1表示没有符合条件的字符 f29 := func(c rune) bool { return unicode.Is(unicode.Han, c) } p("LastIndexFunc:", s.LastIndexFunc("Hello, 世界", f29)) //LastIndexFunc: 10 p("LastIndexFunc:", s.LastIndexFunc("Hello, world", f29)) //LastIndexFunc: -1 //30. func Trim(s string, cutset string) string //Trim 去除字符串s两端满足cutset的字符 p("Trim:", s.Trim("¡¡¡Hello! Gophers!!!", "!¡")) //Trim: Hello! Gophers //31. func TrimLeft(s string, cutset string) string //TrimLeft 去除字符串s左端满足cutset的字符 p("TrimLeft:", s.TrimLeft("¡¡¡Hello! Gophers!!!", "!¡")) //TrimLeft: Hello! Gophers!!! //32. func TrimRight(s string, cutset string) string //TrimRight 去除字符串s右端满足cutset的字符 p("TrimRight:", s.TrimRight("¡¡¡Hello! Gophers!!!", "!¡")) //TrimRight: ¡¡¡Hello! Gophers //33. func TrimSpace(s string) string //TrimSpace 去除s两端的空白符 //var asciiSpace = [256]uint8{'\t': 1, '\n': 1, '\v': 1, '\f': 1, '\r': 1, ' ': 1} p("TrimSpace:", s.TrimSpace(" ab cd eef \t ")) //TrimSpace: ab cd eef //34. func TrimPrefix(s, prefix string) string //TrimPrefix 去除字符串s的前缀,如果不是,则返回s p("TrimPrefix:", s.TrimPrefix("abcabcab", "abc")) //TrimPrefix: abcab p("TrimPrefix:", s.TrimPrefix("abcabcab", "ac")) //TrimPrefix: abcabcab //35. func TrimSuffix(s, suffix string) string //TrimSuffix 去除字符串s的后缀,如果不是,则返回s p("TrimSuffix:", s.TrimSuffix("abcabcab", "ab")) //TrimSuffix: abcabc p("TrimSuffix:", s.TrimSuffix("abcabcab", "ac")) //TrimSuffix: abcabcab //36. func Replace(s, old, new string, n int) string //Replace 将字符串s中的old替换为new,如果old为空,将s中每个字符前后插入new,即len(s)+1个new // n < 0,不限制替换的个数;n = 0,不替换;n > 0,最多替换n个 p("Replace:", s.Replace("abcbcbc", "cb", "cbd", -1)) //Replace: abcbdcbdc p("Replace:", s.Replace("abcbcbc", "", "cbd", -1)) //Replace: abcbdcbdc p("Replace:", s.Replace("abcbcbc", "cb", "cbd", 0)) //Replace: abcbcbc p("Replace:", s.Replace("abcbcbc", "cb", "cbd", 1)) //Replace: abcbdcbc //37. func EqualFold(s, t string) bool //EqualFold 判断字符串s、t是否相等,大小写不敏感 p("EqualFold:", s.EqualFold("abca", "ABcA")) //EqualFold: true p("EqualFold:", s.EqualFold("abca", "abcd")) //EqualFold: false p("EqualFold:", s.EqualFold("中国", "中国")) //EqualFold: true //38. func Index(s, substr string) int //Index 返回substr在s中第一次出现的位置,-1表示未出现 p("Index:", s.Index("abc", "bc")) //Index: 1 p("Index:", s.Index("abc", "bd")) //Index: -1 }4. 字符串和其他类型的转换
strconv包实现了字符串与基础类型的相互转换。4.1 数字转换
最常用的字符转换是,字符串转整数
Atoi和整数转字符串Itoa。(此时假设都是十进制)i, err := strconv.Atoi("-42") s := strconv.Itoa(-42)4.2
Prase相关函数–字符串转为其他ParseBool,ParseFloat,ParseInt, 和ParseUint将字符串转为相应类型。b, err := strconv.ParseBool("true") f, err := strconv.ParseFloat("3.1415", 64) i, err := strconv.ParseInt("-42", 10, 64) u, err := strconv.ParseUint("42", 10, 64)prase函数(float64, int64, and uint64)默认放回的是64位,但是可以通过转换,变成需要的类型,如下。
s := "2147483647" // biggest int32 i64, err := strconv.ParseInt(s, 10, 32) //... i := int32(i64)4.3
Format相关函数–其他类型转为字符串FormatBool,FormatFloat,FormatInt, 和FormatUint将值转为字符串。s := strconv.FormatBool(true) s := strconv.FormatFloat(3.1415, 'E', -1, 64) s := strconv.FormatInt(-42, 16) s := strconv.FormatUint(42, 16)4.4
Append相关函数–字符串追加值AppendBool,AppendFloat,AppendInt和AppendUint将格式化后的字符追加到des后面。4.5
Quote相关函数Quote将字符串转为转义字符串,运行一下。fmt.Printf("%#v\n", sc.QuoteToASCII(`Hello, 世界`)) //"\"Hello, \\u4e16\\u754c\"" fmt.Printf("%#v\n", sc.Quote("Hello, \t世界")) //"\"Hello, \\t世界\"" fmt.Printf("%#v\n", "Hello, 世界") //"Hello, 世界" str, _ := sc.Unquote(sc.Quote(`Hello, 世界`)) fmt.Printf("%#v\n", str) //"Hello, 世界"4.6
strconv常用例子strconv包中常见的例子,运行一下。package main import ( "fmt" sc "strconv" ) var p = fmt.Println func main() { //1. func ParseBool(str string) (bool, error) //ParseBool 解析字符串str的bool值,其他值返回错误 //接受值为:1, t, T, TRUE, true, True, 0, f, F, FALSE, false, False. resp1, err1 := sc.ParseBool("True") p("ParseBool:", resp1, err1) //ParseBool: true <nil> resp1, err1 = sc.ParseBool("0") p("ParseBool:", resp1, err1) //ParseBool: false <nil> resp1, err1 = sc.ParseBool("yes") p("ParseBool:", resp1, err1) //ParseBool: false strconv.ParseBool: parsing "yes": invalid syntax //2. func FormatBool(b bool) string //FormatBool 根据传入的布尔值b,返回true or false p("FormatBool:", sc.FormatBool(true)) //FormatBool: true p("FormatBool:", sc.FormatBool(false)) //FormatBool: false //3. func AppendBool(dst []byte, b bool) []byte //AppendBool 根据b的值,将"true"或"false"追加到dst后,并返回结果 var byteVar3 []byte p("AppendBool:", string(sc.AppendBool(byteVar3, false))) //AppendBool: false p("AppendBool:", string(sc.AppendBool(byteVar3, true))) //AppendBool: true //`...`是golang中的语法糖,跟在slice后面可以将slice打散成元素类型,也可以在函数入参作为不定参 // slice = append([]byte("hello "), "world"...) // func append(slice []Type, elems ...Type) []Type //4. func ParseFloat(s string, bitSize int) (float64, error) //ParseFloat 将字符串s转为float,根据bitSize是32或64转为float32或float64 resp4, err4 := sc.ParseFloat("3.14", 64) p("ParseFloat:", resp4, err4) //ParseFloat: 3.14 <nil> resp4, err4 = sc.ParseFloat("3.1415926", 32) p("ParseFloat:", resp4, err4) //ParseFloat: 3.141592502593994 <nil> resp4, err4 = sc.ParseFloat("3.14f", 64) p("ParseFloat:", resp4, err4) //ParseFloat: 0 strconv.ParseFloat: parsing "3.14f": invalid syntax //5. func FormatFloat(f float64, fmt byte, prec, bitSize int) string //FormatFloat 根据fmt和prec将f转为字符串;prec表示精度,负数表示保留全部,非负数表示保留小数 //fmt 取值如下 // 'b' (-ddddp±ddd, a binary exponent), // 'e' (-d.dddde±dd, a decimal exponent), // 'E' (-d.ddddE±dd, a decimal exponent), // 'f' (-ddd.dddd, no exponent), // 'g' ('e' for large exponents, 'f' otherwise), or // 'G' ('E' for large exponents, 'f' otherwise). p("FormatFloat:", sc.FormatFloat(3.1415926, 'f', -5, 64)) //FormatFloat: 3.1415926 p("FormatFloat:", sc.FormatFloat(3.1415926, 'f', 2, 64)) //FormatFloat: 3.14 //6. func AppendFloat(dst []byte, f float64, fmt byte, prec, bitSize int) []byte //AppendFloat 将f根据fmt、prec转为字符串,然后追加到dst后返回 var byteVar6 []byte = []byte{'3', '1'} p("AppendFloat:", string(sc.AppendFloat(byteVar6, 3.1415926, 'f', -5, 64))) //AppendFloat: 313.1415926 p("AppendFloat:", string(sc.AppendFloat(byteVar6, 3.1415926, 'f', 3, 64))) //AppendFloat: 313.142 //7. func ParseInt(s string, base int, bitSize int) (i int64, err error) //ParseInt 将字符串s转为整数 // 进制base 取值[2, 36],取0自动检测字符串的进制 // Bit sizes 0, 8, 16, 32, and 64. For a bitSize below 0 or above 64 an error is returned. resp7, err7 := sc.ParseInt("123456", 0, 64) p("ParseInt:", resp7, err7) //ParseInt: 123456 <nil> resp7, err7 = sc.ParseInt("3.14", 0, 64) p("ParseInt:", resp7, err7) //ParseInt: 0 strconv.ParseInt: parsing "3.14": invalid syntax resp7, err7 = sc.ParseInt("0123456", 0, 64) p("ParseInt:", resp7, err7) //ParseInt: 42798 <nil> resp7, err7 = sc.ParseInt("10101", 1, 64) p("ParseInt:", resp7, err7) //ParseInt: 0 strconv.ParseInt: parsing "10101": invalid base 1 //8. func ParseUint(s string, base int, bitSize int) (uint64, error) //ParseUint 将字符串s转为整数,参数取值通ParseInt resp8, err8 := sc.ParseUint("123456", 0, 64) p("ParseUint:", resp8, err8) //ParseUint: 123456 <nil> resp8, err8 = sc.ParseUint("-123456", 0, 64) p("ParseUint:", resp8, err8) //ParseUint: 0 strconv.ParseUint: parsing "-123456": invalid syntax //9. func Atoi(s string) (int, error) //Atoi 将字符串s转为十进制的int resp9, err9 := sc.Atoi("1234") p("Atoi:", resp9, err9) //Atoi: 1234 <nil> resp9, err9 = sc.Atoi("-1234") p("Atoi:", resp9, err9) //Atoi: -1234 <nil> //10. func Itoa(i int) string //Itoa 将int i转为字符串 p("Itoa:", sc.Itoa(1234)) //Itoa: 1234 p("Itoa:", sc.Itoa(-1234)) //Itoa: -1234 //11. func FormatInt(i int64, base int) string //FormatInt 将整数i转为指定进制的整数 //base 取值[2, 36],用a-z表示大于等于10的数;base取其他值panic p("FormatInt:", sc.FormatInt(15, 2)) //FormatInt: 1111 p("FormatInt:", sc.FormatInt(0x15, 8)) //FormatInt: 25 p("FormatInt:", sc.FormatInt(37, 36)) //FormatInt: 11 // p("FormatInt:", sc.FormatInt(37, 37)) //panic //12. func FormatUint(i uint64, base int) string //FormatUint 将正整数i转为指定进制的整数 //base 取值[2, 36],用a-z表示大于等于10的数;base取其他值panic p("FormatUint:", sc.FormatUint(15, 2)) //FormatUint: 1111 //13. func AppendInt(dst []byte, i int64, base int) []byte //AppendInt 将i转为base进制的字符串,追加到dst后 var byteVar13 = []byte{'1'} p("AppendInt:", string(sc.AppendInt(byteVar13, 15, 2))) //AppendInt: 11111 //14. func AppendUint(dst []byte, i uint64, base int) []byte //AppendUint 将i转为base进制的字符串,追加到dst后 var byteVar14 = []byte{'1'} p("AppendUint:", string(sc.AppendUint(byteVar14, 15, 2))) //AppendUint: 11111 //15. func Quote(s string) string //Quote p("Quote:", sc.Quote("Hello, \t世界")) //Quote: "Hello, \t世界" p("WithoutQuote:", "Hello, \t世界") //WithoutQuote: Hello, 世界 //16. func Unquote(s string) (string, error) //Unquote resp16, err16 := sc.Unquote(sc.Quote("Hello, \t世界")) p("Unquote:", resp16, err16) //Unquote: Hello, 世界 <nil> }